类别
内容
诊断流程
基本概念
异常诊断流程
常见客户端报错
排查思路
排查思路
常见排查方法
检查业务Pod的DNS配置
检查CoreDNS Pod运行状态
检查CoreDNS运行日志
检查CoreDNS DNS查询请求日志
检查CoreDNS Pod的网络连通性
检查业务Pod到CoreDNS的网络连通性
抓包
常见问题及解决方案
集群外部域名解析异常
新增Headless类型域名无法解析
StatefulSets Pod域名无法解析
安全组、交换机ACL配置错误
容器网络连通性异常
CoreDNS Pod负载高
CoreDNS Pod负载不均
CoreDNS Pod运行状态异常
客户端负载原因导致解析失败
Conntrack表满
AutoPath插件异常
A记录和AAAA记录并发解析异常
IPVS缺陷导致解析异常
NodeLocal DNSCache未生效
PrivateZone域名解析异常
诊断流程基本概念集群内部域名:CoreDNS会将集群中的服务暴露为集群内部域名,默认以.cluster.local结尾,这类域名的解析通过CoreDNS内部缓存完成,不会从上游DNS服务器查询。
集群外部域名:在第三方DNS服务商、阿里云DNS云解析、PrivateZone等产品注册的权威解析,这类域名由CoreDNS的上游DNS服务器负责解析,CoreDNS仅做解析请求转发。
业务Pod:您部署在Kubernetes集群中的容器Pod,不包含Kubernetes自身系统组件的容器。
接入CoreDNS的业务Pod:容器内DNS服务器指向了CoreDNS的业务Pod。
接入NodeLocal DNSCache的业务Pod:集群中安装了NodeLocal DNSCache插件后,通过自动或手动方式注入DNSConfig的业务Pod。这类Pod在解析域名时,会优先访问本地缓存组件。如果访问本地缓存组件不通时,会访问CoreDNS提供的kube-dns服务。
异常诊断流程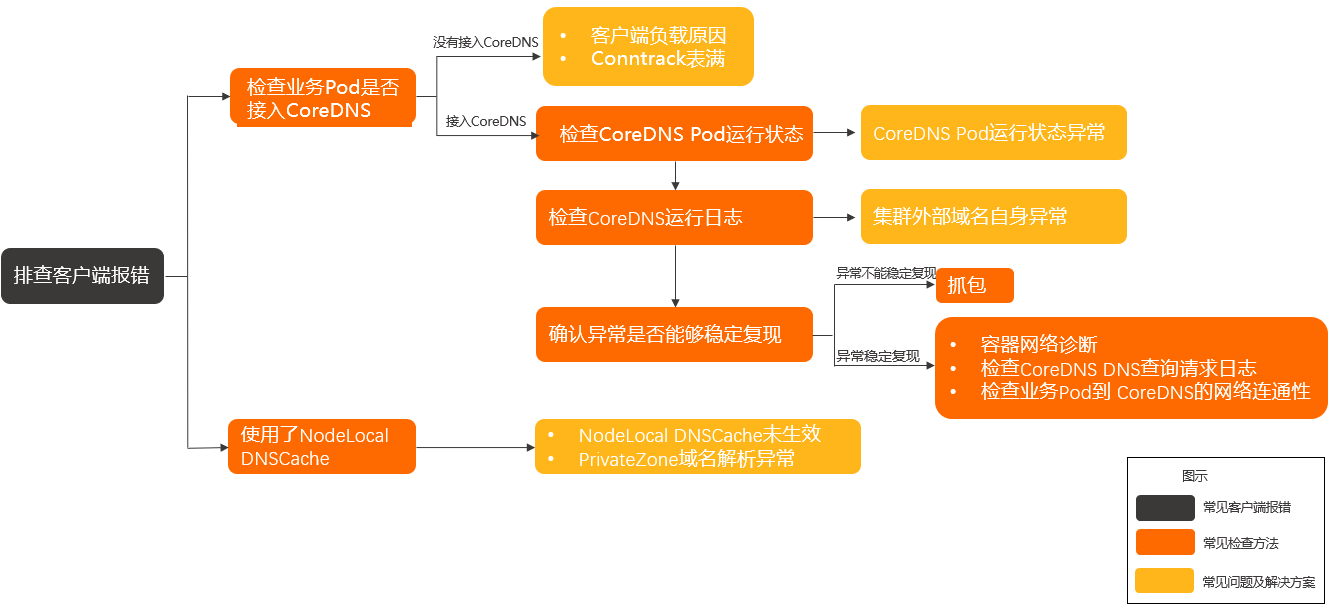
判断当前的异常原因。具体信息,请参见常见客户端报错。
如果异常原因是域名不存在,请参见排查思路的《按解析异常的域名类型》。
如果异常原因是无法连接至域名服务器,请参见排查思路的《按解析异常出现频次》。
如果以上排查无果,请按以下步骤排查。
检查业务Pod的DNS配置,是否已经接入CoreDNS。具体操作,请参见检查业务Pod的DNS配置。
如果没有接入CoreDNS,则考虑是客户端负载原因或Conntrack表满导致解析失败。具体操作,请参见客户端负载原因导致解析失败和Conntrack表满。
如果接入了CoreDNS,则按以下步骤排查。
通过检查CoreDNS Pod运行状态进行诊断。具体操作,请参见检查CoreDNS Pod运行状态和CoreDNS Pod运行状态异常。
通过检查CoreDNS运行日志进行诊断。具体操作,请参见检查CoreDNS运行日志和集群外部域名解析异常。
确认异常是否能够稳定复现。
如果异常稳定复现,请参见检查CoreDNS DNS查询请求日志和检查业务Pod到CoreDNS的网络连通性。
如果异常不能稳定复现,请参见抓包。
如果使用了NodeLocal DNSCache,请参见NodeLocal DNSCache未生效和PrivateZone域名解析异常。
如果以上排查无果,请提交工单排查。
常见客户端报错客户端
报错日志
可能异常
ping
ping: xxx.yyy.zzz: Name or service not known
域名不存在或无法连接域名服务器。如果解析延迟大于5秒,一般是无法连接域名服务器。
curl
curl: (6) Could not resolve host: xxx.yyy.zzz
PHP HTTP客户端
php_network_getaddresses: getaddrinfo failed: Name or service not known in xxx.php on line yyy
Golang HTTP客户端
dial tcp: lookup xxx.yyy.zzz on 100.100.2.136:53: no such host
域名不存在。
dig
;; ->>HEADER100.100.2.136:53: i/o timeout
日志出现时间段内,CoreDNS无法连接到上游DNS服务器。
客户端负载原因导致解析失败问题现象业务高峰期间或突然偶发的解析失败,ECS监控显示机器网卡重传率、CPU负载有异常。
问题原因接入CoreDNS的业务Pod所在ECS负载达到100%等情况导致UDP报文丢失。
解决方案建议提交工单排查原因。
考虑采用NodeLocal DNSCache缓存方案,提升DNS解析性能,降低CoreDNS负载。具体操作,请参见使用NodeLocal DNSCache。
Conntrack表满问题现象部分节点或全部节点上接入CoreDNS的业务,Pod解析域名在业务高峰时间段内出现大批量域名解析失败,高峰结束后失败消失。
运行dmesg -H,滚动到问题对应时段的日志,发现出现conntrack full字样的报错信息。
问题原因Linux内Conntrack表条目有限,无法进行新的UDP或TCP请求。
解决方案增加Conntrack表限制。具体操作,请参见如何提升Linux连接跟踪Conntrack数量限制?。
AutoPath插件异常问题现象解析集群外部域名时,概率性解析失败或解析到错误的IP地址,解析集群内部域名无异常。
高频创建容器时,集群内部服务域名解析到错误的IP地址。
问题原因CoreDNS处理缺陷导致AutoPath无法正常工作。
解决方案按照以下步骤,关闭AutoPath插件。
执行kubectl -n kube-system edit configmap coredns命令,打开CoreDNS配置文件。
删除autopath @kubernetes一行后保存退出。
检查CoreDNS Pod运行状态和运行日志,运行日志中出现reload字样后说明修改成功。
A记录和AAAA记录并发解析异常问题现象接入CoreDNS的业务Pod解析域名概率性失败。
从抓包或检查CoreDNS DNS查询请求日志可以发现,A和AAAA通常在同一时间的出现,并且请求的源端口一致。
问题原因并发A和AAAA的DNS请求触发Linux内核Conntrack模块缺陷,导致UDP报文丢失。
解决方案考虑采用NodeLocal DNSCache缓存方案,提升DNS解析性能,降低CoreDNS负载。具体操作,请参见使用NodeLocal DNSCache。
CentOS、Ubuntu等基础镜像,可以通过options timeout:2 attempts:3 rotate single-request-reopen等参数优化。
如果容器镜像是以Alpine制作的,建议更换基础镜像。